- Présentation
- Installation de l'outil
- Lancement de l'outil
- Choix du résultat
- Connexion à l'outil
- Interface utilisateur
- Analyse et comparaison des données
- Données à analyser
- Colonnes à comparer
- Méthodes de comparaison
- Résultat de l'analyse
- Recherche des doublons
- Validation de doublons
- Sauvegarde des doublons validés
- Paramétrage
- Base de données analysée
- Sauvegarde de la configuration
- Nombre de lignes de données traitées
Présentation
L'objectif de cet outil intégré dans le module de dédoublonnage de données est de détecter des doublons parmi des données selon certains critères. Il s'agit de mettre en évidence des couples de données similaires afin de les supprimer.
Ainsi, si deux tiers possèdent un nom semblable, on peut se demander s'il ne s'agit du même tiers représentant la même personne ou la même entreprise. Il en va de même pour les adresses physiques ou mail.
L'interface utilisateur de l'outil est en anglais.
Installation de l'outil
L'outil de dédoublonnage de données doit faire l'objet d'une installation "locale", c'est-à-dire de l'installation des composants
- soit directement sur le poste de l'utilisateur ;
- soit sur un serveur de fichiers.
Première installation :
Pour installer l'outil, il suffit de récupérer l'archive d'installation et de la décompresser dans le répertoire souhaité (local ou centralisé).
La page de téléchargement est construite de la manière suivante :
- Récupérer l'URL de connexion à l'interface utilisateur. Exemple : http://serveur/environnement/xxxxx.html
- Remplacer dans celle-ci la chaîne commençant à partir du terme "/xxxxx.html" inclus, par "/tools/ddu/index.html". Exemple : http://serveur/environnement/tools/ddu/index.html
Une fois l'archive récupérée, à l'aide d'un outil de décompression, extraire le contenu de l'archive, dans le répertoire souhaité.
Les composants sont générés dans un répertoire racine appelé "qualiactools".
L'installation d'un environnement JAVA n'est pas nécessaire car le kit d'installation en embarque déjà un.
Mises à jour ultérieures :
A l'occasion de passage de patch ou d'une nouvelle version et sauf indications contraires, il faudra réitérer cette procédure en décompressant l'archive d'installation, dans le même répertoire.
Lancement de l'outil
Pour lancer l'outil de dédoublonnage des données, exécuter le fichier qualiacddu.cmd présent dans le répertoire d'installation de l'outil.
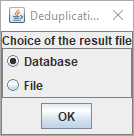
Choix du résultat
Tout d'abord, il faut choisir si le résultat de l'outil sera sous forme d'un fichier ou s'il sera enregistré dans la base de données.
Dans certain cas, le poste utilisateur ne peut pas accéder au serveur de base de données, dans ce cas, il convient de choisir "File".
Connexion à l'outil
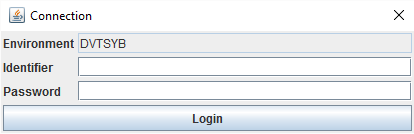
Pour le cas où l'utilisateur choisi l'option "Database" (base de données), l'outil s'appuie sur des déclarations consignées dans un fichier bien particulier : qualiacdb.properties. Ce dernier doit être placé au même niveau que le fichier à exécuter qualiacddu.cmd.
Ce fichier est normalement généré par le service de téléchargement invoqué à l'occasion de la procédure d'installation. Si tel n'est pas le cas, il pourra être récupéré sur le serveur de traitements ($IAC_HOME/local) ou sur le serveur web (%QUALIACWEB_HOME\WEB-INF\classes en général).
Les informations saisies devront permettre au poste sur lequel l'outil est exécuté d'accéder à la base via un nom de machine (ou adresse IP), port et nom de la base.
La base de données accessible par l'outil (champ "Environment") est la base de données définie par défaut dans le fichier qualiacdb.properties.
Une fois ces informations paramétrées, il faut se connecter à la base de données, pour cela saisir un utilisateur existant et son mot de passe.
Interface utilisateur
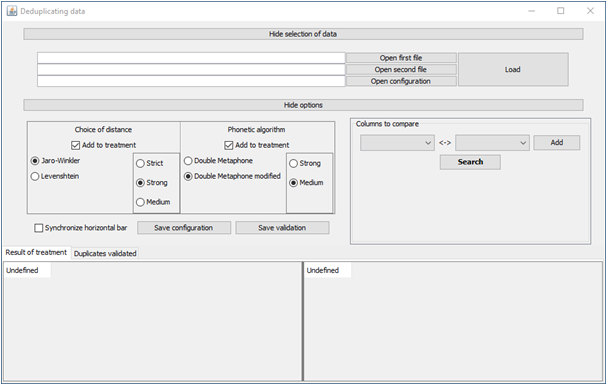
Ensuite, si la connexion est correcte, l'interface utilisateur se présente ainsi :
- la partie haute permet de sélectionner les fichiers dans lesquels se trouvent les données à analyser ;
- la partie centrale gauche sert à choisir les différentes méthodes de comparaison ;
- la partie centrale droite permet de sélectionner les colonnes des fichiers à comparer ;
- la partie centrale basse affiche le résultat du traitement.
Analyse et comparaison des données
Données à analyser
Les données à analyser sont présentes dans un ou deux fichiers.
La structure de ces fichiers doit être de la forme colonnes, lignes. Les colonnes sont séparées par des points-virgules et les lignes par des "retours à la ligne".
S'il s'agit de fichiers d'export générés depuis l'interface utilisateur, il faut exporter les données avec comme séparateur ";" et l'extension "txt". L'extension "csv" est déconseillée car pour une compatibilité avec Excel, on entoure automatiquement les données avec =("VALEUR").
La première ligne de ces fichiers doit contenir le nom des colonnes séparées par ";".
Colonnes à comparer
Une fois le ou les fichiers à analyser renseignés, appuyer sur le bouton "Load" pour charger les en-têtes de colonnes. Puis, spécifier, via les listes déroulantes (contenant le nom des colonnes), les colonnes à comparer.
On peut ainsi ajouter ou supprimer des correspondances de colonnes. Au fur et à mesure que cela se fait, les correspondances sont affichées avec la méthode de comparaison en cours de sélection.
Méthodes de comparaison
Quatre méthodes sont utilisables :
Distance de Jaro-Winkler
Echelle de comparaison efficace entre deux chaînes de caractères. Donne plus d'importance au début des chaînes de caractères. Elle est adaptée pour la comparaison de chaînes de caractères courtes comme par exemple les noms ou les prénoms.
Distance de Levenshtein
Calcul du nombre de remplacements, d'insertions ou de suppressions de caractères à réaliser pour passer d'une chaîne de caractères à l'autre.
Niveaux de distance :
- Strict : les deux chaînes de caractères doivent être identiques ;
- Fort : les deux chaînes de caractères doivent être fortement similaires ;
- Moyen : les deux chaînes de caractères doivent être similaires.
Algorithmes phonétiques : Double Metaphone
Méthode calculant un code qui représente la prononciation de la chaîne de caractères. Elle est moyennement adaptée au français et le code ne dépasse pas 4 caractères.
Algorithmes phonétiques : Double Metaphone modifié
Cette méthode fait appel à la méthode "Double Metaphone" et corrige les fins de code pour être plus adaptée au français. La longueur du code peut aller jusqu'à 100 caractères.
Niveaux phonétiques :
- Fort : les deux codes doivent être identiques ;
- Moyen : les deux codes doivent être similaires.
Résultat de l'analyse
Recherche des doublons
Suivant les méthodes de comparaison précédemment indiquées, via le bouton "Search", l'outil compare les données des colonnes sélectionnées et affiche le résultat dans deux tableaux.
Les lignes de données qui sont :
- certainement des doublons en rouge ;
- probablement des doublons en orange ;
- possiblement des doublons en orange plus clair.
L'outil affiche côte à côte les lignes de données concernées des deux fichiers.
Validation de doublons
Par l'intermédiaire d'un menu (clic droit) sur la ligne de données d'un des deux tableaux de résultats, un doublon peut être validé. Cela supprime le doublon des deux tableaux de l'onglet "Result of treatment" pour l'insérer dans les deux tableaux de l'onglet "Duplicates validated".
Sauvegarde des doublons validés
Lorsque tous les doublons sont validés par l'utilisateur, il faut sauvegarder le résultat via le bouton "Save validation".
Suivant le choix que l'on a fait au lancement de l'outil, deux cas sont possibles : soit d'enregistrer le résultat en base de données soit dans un fichier.
Les doublons validés s'enregistrent dans la base de données (table GTDDU).
Afin d'enregistrer ce résultat, il faut préalablement spécifier les colonnes qui représentent l'index unique des données des deux fichiers. Pour cela, cocher chaque en-tête de colonnes représentant cet index dans les deux tableaux de l'onglet "Result of treatment". Ce sont les valeurs de ces colonnes "index" qui sont enregistrées dans la table GTDDU.
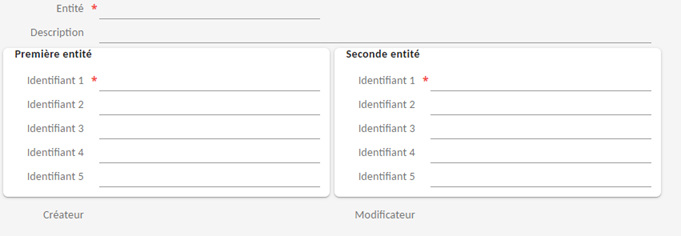
Ecran de sauvegarde des doublons :
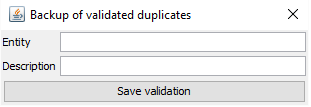
La zone "Entity" sert à regrouper, dans la table GTDDU, les doublons représentant un même type de données sous le même nom (par exemple TIERS, ARTICLES, FOURNISSEURS).
Ensuite dans l'interface utilisateur, une transaction (mnémonique GTDDU) permet de visualiser le contenu de la table GTDDU. Le champ "Entité" est utilisé pour rechercher les doublons par type.
Les doublons validés s'enregistrent dans un fichier.
La structure du fichier est de la forme colonnes, lignes.
Afin d'enregistrer ce fichier, il faut préalablement spécifier les colonnes qui représentent l'index unique des données des deux fichiers. Pour cela, cocher chaque en-tête de colonnes représentant cet index dans les deux tableaux de l'onglet "Result of treatment". Ce sont les valeurs de ces colonnes "index" qui seront les en-têtes des colonnes du fichier généré.
Ensuite, une boite s'ouvre demandant l'emplacement et le nom du fichier résultat.
Paramétrage
Base de données analysée
La base de données à analyser s'affiche dans la fenêtre de connexion à l'outil. Cette base de données est définie dans le fichier qualiacdb.properties se trouvant dans le même répertoire que le fichier à exécuter qualiacddu.cmd.
Sauvegarde de la configuration
Il est possible de sauvegarder dans un fichier les correspondances de colonnes à comparer ainsi que les index des fichiers de données avec le bouton "Save configuration".
Lors d'une prochaine comparaison du même jeu de données, cette sauvegarde est réutilisable en activant le bouton "Open configuration".
Nombre de lignes de données traitées
Afin de ne pas saturer la mémoire des serveurs, par défaut l'outil est configuré pour traiter 5000 lignes de doublons. Cette limite est paramétrable en modifiant le fichier qualiacddu.cmd qui lance l'outil.
Exemple de contenu dans le fichier "cmd "si l'outil traite 7500 lignes :
%JAVA% -Xms128m -Xmx512m -cp %CLASSPATH% -Djava.library.path=%CURDIR% com.qualiac.ddu.Main -NB 7500